本地部署Deepseek和阿里Qwen,并在桌面及VsCode中使用
文章目录
本文主要实现在 Windows 系统下通过 Miniconda 手动创建 Python 运行环境,本地部署 Deepseek 和阿里 Qwen,并在桌面环境中使用,包括 Text Generation Web UI(简称TGW,通常被称为“oobabooga”)创建类 StableDiffusion WebUI前端交互界面,Cherry-Studio 客户端,与 VS Code 集成。
创建 Python 运行环境
目前 TGW 环境使用的是 CUDA 12.1 版本,使用 conda 安装 CUDA 12.1 运行环境和 PyTorch-GPU 2.5.1。
|
|
TGW(Text Generation WebUI)
|
|
在 Windows 环境下安装的 flash-attention 运行时会报如下错误:
|
|
需要手动安装网友编译的 flash-attention Windows 版本https://github.com/bdashore3/flash-attention/releases,这里我们选用 flash_attn-2.7.1.post1+cu124torch2.5.1cxx11abiFALSE-cp311-cp311-win_amd64.whl。
在完成所需包的安装之后,您需要准备模型,将模型文件或目录放在 TGW 的 ./models 文件夹中。可以在 huggingface 网站下载单个 GGUF 类型模型文件,或者将整个 Transformer 模型文件夹放到 models 文件夹中。
|
|
在 Model 选项卡中选择要使用的模型并 Load
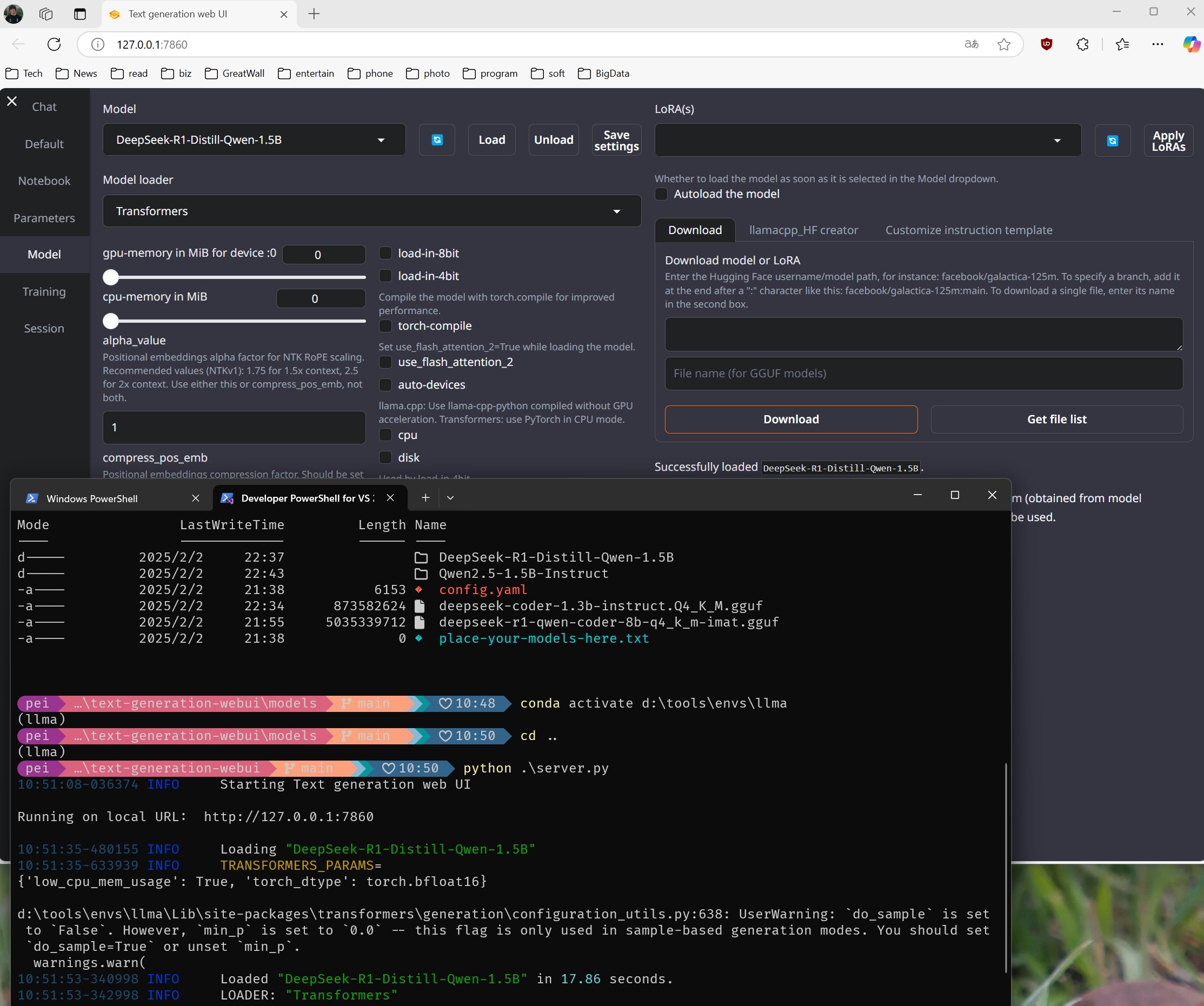
WebUI 交互示意
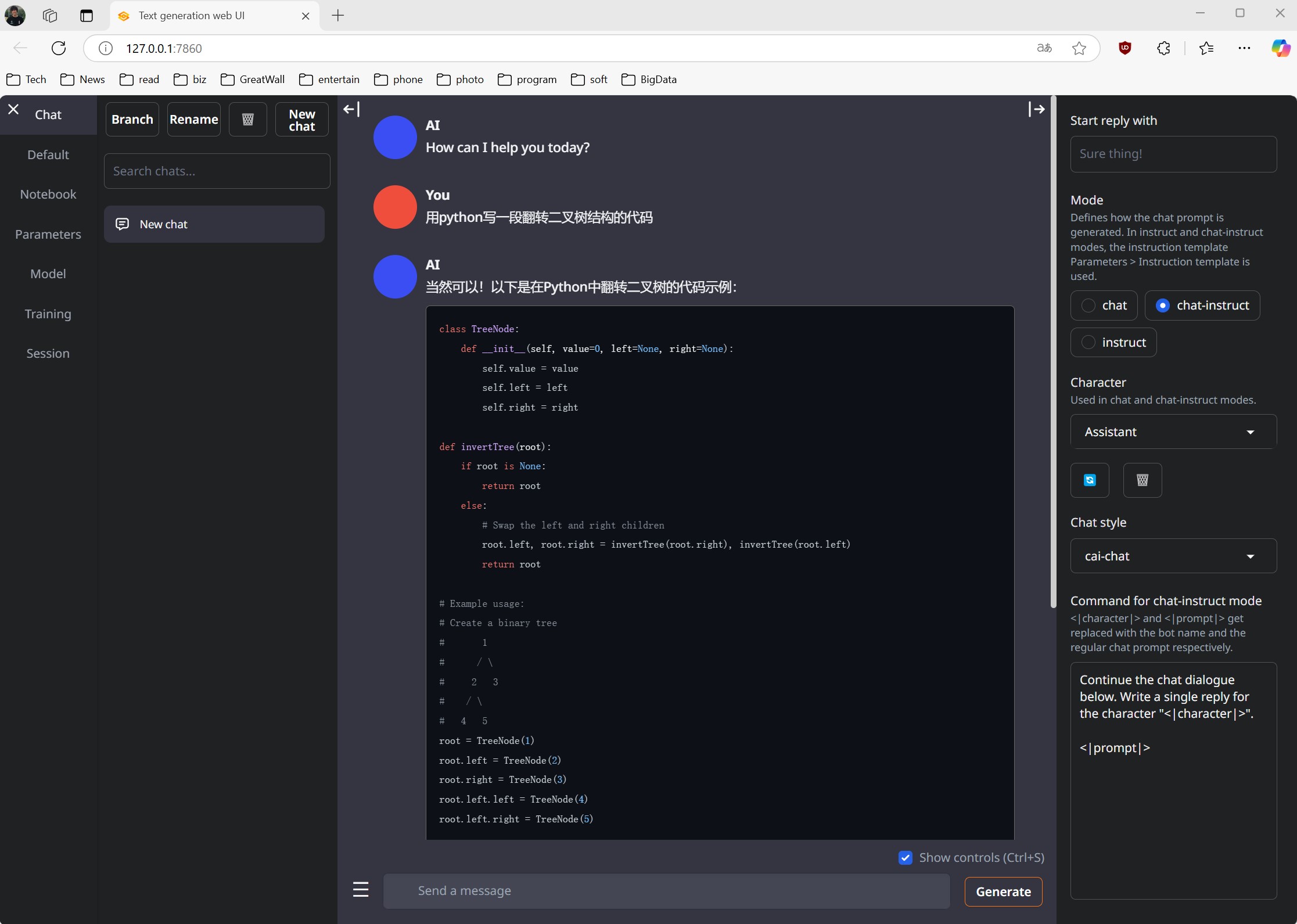
模型运行方式
其它本地部署运行方式有:
- ollama
- vLLM
- LM Studio
- llama.cpp
这里我们使用比较原始的方式,llama.cpp, 下载对应系统的包,比如 Windows CUDA 上 llama-bXXXX-bin-win-cuda-cu12.4-x64.zip
|
|
桌面客户端 Cherry-Studio
跨平台桌面客户端 Cherry-Studio,手动添加模型服务
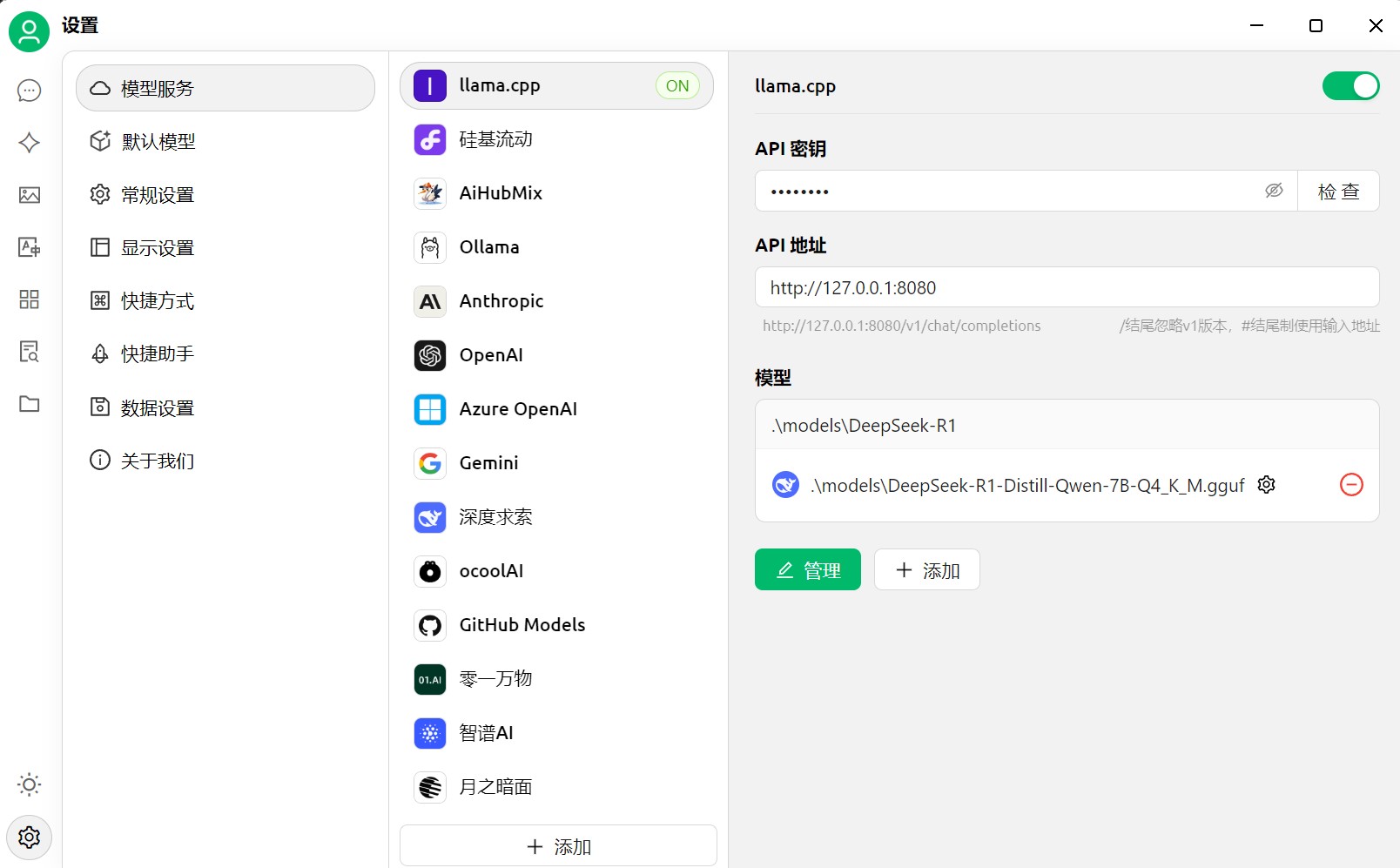
VS Code集成
使用 continue 扩展(其它可选 cline / RooCode),模型增加配置
|
|
文章作者
上次更新 2025-02-03